GPT-5.5 est sorti le 23 avril 2026, 48 jours après GPT-5.4. OpenAI a fait quelque chose d’inhabituel : avertir publiquement que vos anciens prompts risquent de freiner les performances du nouveau modèle. Pas un argument commercial, une mise en garde technique. Ce guide compare les deux modèles sur ce qui compte pour les équipes marketing : cohérence de ton, gestion du contexte long, précision factuelle et efficacité des prompts de copywriting.
Ce qui a changé entre GPT-5.4 et GPT-5.5
GPT-5.4 est sorti début mars 2026. Il apportait un vrai saut sur l’utilisation ordinateur (computer use à 75% sur OSWorld), un contexte natif d’un million de tokens (avec tarification majorée au-delà de 272 000 tokens) et un score d’environ 58% sur SWE-Bench Verified. Pour les marketeurs, son principal avantage était une réduction de 33% des erreurs factuelles par rapport à GPT-5.2 et une meilleure tenue du ton sur des textes longs.
GPT-5.5 est une refonte de base. Les versions 5.0 à 5.4 étaient des itérations post-entraînement sur la même architecture. GPT-5.5 a été réentraîné depuis ses fondations. Les gains se concentrent sur trois points : gestion des contextes très longs, réduction des hallucinations et autonomie dans les tâches multi-étapes.
Le changement le plus concret pour le marketing : GPT-5.5 tient la cohérence de voix sur toute la durée d’une conversation. Avec GPT-5.4, le ton dérivait après plusieurs échanges couvrant des sujets variés, ce qui forçait les équipes à répéter les instructions de brand voice à chaque nouveau message. Ce comportement a disparu.
Benchmarks comparés : GPT-5.4 vs GPT-5.5
Les données ci-dessous sont issues des publications des éditeurs lors des lancements respectifs (vendor-reported). Elles permettent de comparer les deux modèles sur les dimensions les plus utiles pour les usages marketing et de traitement de contenu.
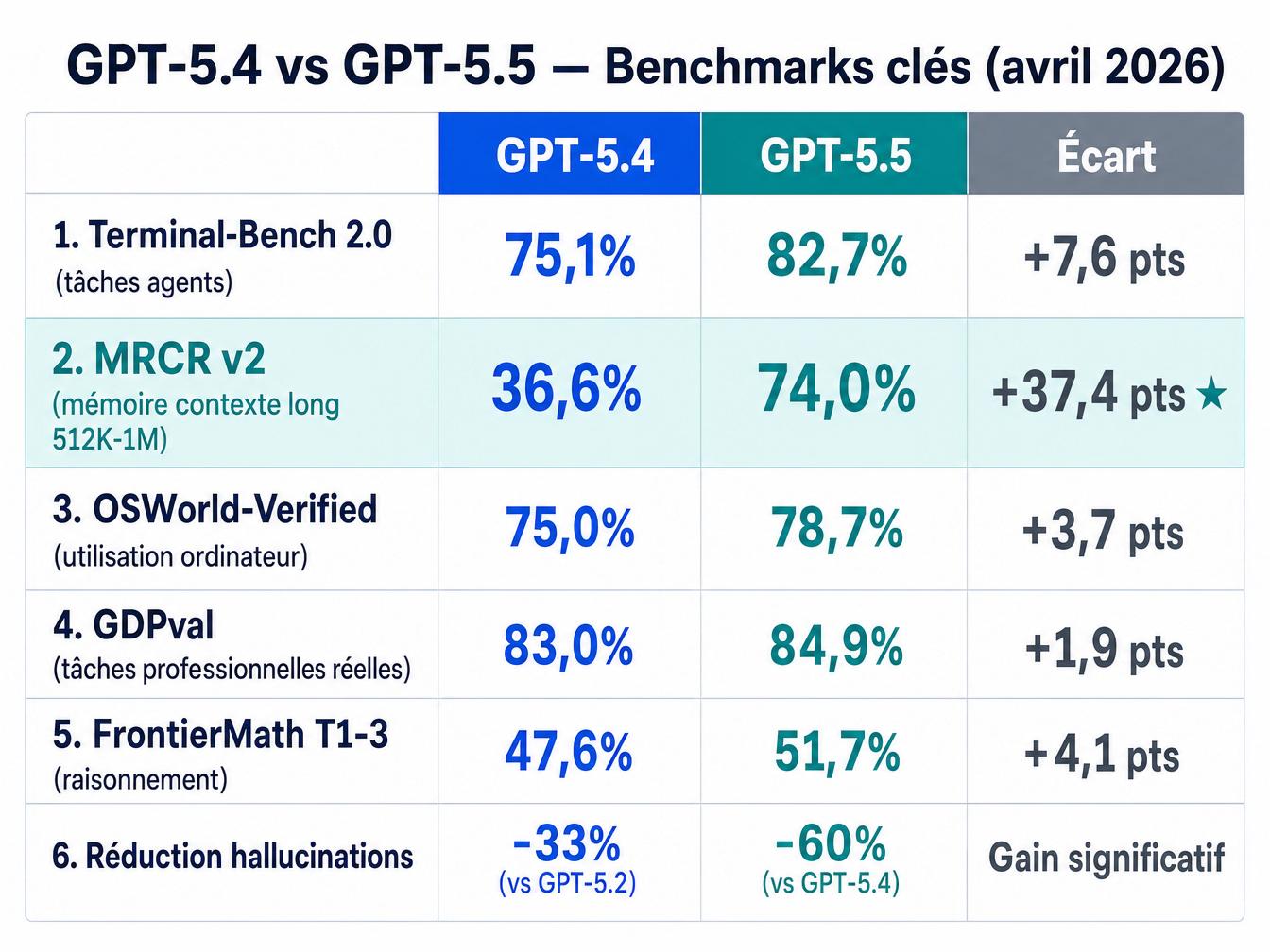
| Benchmark | GPT-5.4 | GPT-5.5 | Écart |
|---|---|---|---|
| Terminal-Bench 2.0 (tâches agents) | 75,1% | 82,7% | +7,6 pts |
| MRCR v2 (mémoire contexte long 512K-1M) | 36,6% | 74,0% | +37,4 pts |
| OSWorld-Verified (utilisation ordinateur) | 75,0% | 78,7% | +3,7 pts |
| GDPval (tâches professionnelles réelles) | 83,0% | 84,9% | +1,9 pts |
| FrontierMath T1-3 (raisonnement) | 47,6% | 51,7% | +4,1 pts |
| Réduction hallucinations vs version précédente | -33% (vs GPT-5.2) | -60% (vs GPT-5.4) | Gain significatif |
Le chiffre à retenir pour les équipes marketing : +37 points sur MRCR v2. Ce benchmark mesure la capacité du modèle à retrouver et utiliser des informations précises dans des contextes de 512 000 à 1 million de tokens. En pratique, ça correspond à charger une charte de marque complète, des exemples de copies passées et des personas clients dans un seul contexte, puis produire du contenu cohérent sans perdre les contraintes de départ.
La règle des prompts courts : ce qu’OpenAI recommande pour GPT-5.5
C’est le changement qui déroute le plus les équipes habituées à GPT-5.4 ou GPT-4o. OpenAI l’indique explicitement : les prompts construits pour les versions précédentes, souvent longs, répétitifs et chargés d’instructions redondantes, produisent de moins bons résultats sur GPT-5.5 qu’un prompt court et direct.
GPT-5.4 et ses prédécesseurs avaient besoin d’être guidés pas à pas. Les répétitions aidaient. Les chaînes de raisonnement explicites (chain-of-thought) amélioraient la qualité. Sur GPT-5.5, ces techniques ajoutent du bruit, augmentent le coût en tokens et peuvent créer des conflits d’instructions quand plusieurs formulations de la même règle coexistent dans le prompt.
Trois patterns à éviter sur GPT-5.5 :
- Répéter l’instruction principale sous différentes formulations (« Tu es un expert en copywriting. En tant que spécialiste du contenu. Rappelle-toi que tu écris pour des professionnels. ») : GPT-5.5 ne sait plus quelle version prioriser.
- Les déclencheurs de role-play (« Agis comme si tu étais le directeur marketing de [marque] ») : moins efficaces que de donner directement les contraintes de ton et de style.
- Les emphases du type « c’est très important » : GPT-5.5 ne pondère pas les instructions selon leur emphase stylistique. Un « c’est crucial » n’augmente pas la priorité de la règle.
Comment adapter vos prompts marketing existants
GPT-5.5 comprend mieux l’intention derrière une demande. Il n’a plus besoin qu’on lui décrive le processus pour produire le bon résultat. Un prompt qui décrit ce que vous voulez obtenir surpasse un prompt qui décrit comment y arriver.
Avant (GPT-5.4) :
Tu es un expert en copywriting B2B. Tu vas rédiger un email de prospection. Commence par une accroche qui capte l’attention. Ensuite, présente le problème que rencontre le lecteur. Puis explique comment notre solution le résout. Termine par un appel à l’action clair. Le ton doit être professionnel mais pas formel. Évite le jargon. L’email doit faire environ 150 mots.
Après (GPT-5.5) :
Email de prospection B2B, 150 mots. Ton direct, sans jargon. Problème : [X]. Solution : [Y]. CTA : demande de démo 15 minutes.
La version courte produit des résultats équivalents ou supérieurs sur GPT-5.5, avec un coût en tokens réduit. L’économie n’est pas anecdotique si vous utilisez l’API à grande échelle : GPT-5.5 est facturé 5 dollars par million de tokens en entrée. Un prompt de 800 tokens contre un prompt de 150 tokens, multiplié par 10 000 générations, représente une différence réelle sur la facture mensuelle.
Brand voice et cohérence de ton : où GPT-5.5 fait la différence
La cohérence de ton sur de longues séquences de contenu était le principal point faible de GPT-5.4 pour les équipes de contenu. Sur une conversation multi-tours couvrant plusieurs sujets (article de blog, adaptation LinkedIn, objet d’email, script vidéo), le ton pouvait dériver. Les équipes compensaient en injectant les instructions de brand voice à chaque nouveau message.
Avec GPT-5.5, cette pratique devient inutile et contre-productive. Répéter les règles de ton à chaque message crée de la redondance que le modèle interprète comme du bruit. Définissez la voix de marque une fois dans le system prompt et ne la répétez plus dans les messages utilisateur.
Ce que le system prompt doit contenir pour un usage marketing :
- Ton et registre (ex : « direct, sans fioritures, jamais condescendant »)
- 3 à 5 phrases ou formulations interdites spécifiques à votre marque
- 2 à 3 exemples de copies validées, annotés
- Le contexte d’audience (profil, niveau d’expertise, langue)
GPT-5.5 tient ces contraintes sur 30 à 40 échanges sans dérive mesurable, là où GPT-5.4 commençait à glisser autour du 10e ou 15e échange sur des conversations couvrant plusieurs formats de contenu.
Tarification et accès : ce qui change pour les équipes marketing
GPT-5.4 est tarifé à 2,50 dollars par million de tokens en entrée et 15 dollars en sortie. GPT-5.5 coûte 5 dollars en entrée et 30 dollars en sortie — deux fois plus cher sur les deux lignes. La réduction de 60% des hallucinations peut diminuer le nombre d’itérations nécessaires sur les campagnes complexes, ce qui atténue l’écart en coût total, mais ça dépend entièrement de votre cas d’usage.
| Modèle | Prix entrée (1M tokens) | Prix sortie (1M tokens) | Contexte max |
|---|---|---|---|
| GPT-5.4 | 2,50 $ | 15 $ | 1 000 000 tokens |
| GPT-5.5 | 5 $ | 30 $ | 1 000 000 tokens |
| GPT-5.5 Pro | 30 $ | 180 $ | 1 000 000 tokens |
Pour les équipes marketing qui utilisent l’API pour la génération de contenu à volume, GPT-5.5 standard est le choix logique. Le contexte à 1 million de tokens permet de charger l’intégralité d’une charte éditoriale, des briefs clients et des exemples de copies dans un seul appel. GPT-5.5 Pro est orienté tâches de raisonnement intensif : analyse de données, recherche approfondie.
GDPval et les tâches professionnelles réelles
Le benchmark GDPval évalue les modèles sur 44 métiers réels. GPT-5.5 y obtient 84,9% contre 83,0% pour GPT-5.4. L’écart est faible, mais la composition du benchmark mérite attention : les tâches marketing y sont explicitement représentées, rédaction de briefs, revue de copies, structuration de campagnes.
GPT-5.5 comprend mieux le contexte implicite d’une tâche professionnelle. Quand vous demandez « révise cet objet d’email pour un public CFO », il infère les contraintes du rôle (aversion au risque, lexique financier, préférence pour la densité d’information) sans que vous ayez à les énoncer. Sur GPT-5.4, ces inférences étaient moins fiables.
Quand migrer, quand rester sur GPT-5.4
Si vous générez du contenu à haute valeur via l’API, migrer vers GPT-5.5 maintenant est défendable. Le tarif d’entrée est deux fois plus élevé (5 $ contre 2,50 $ pour GPT-5.4), mais la réduction de 60% des hallucinations diminue le nombre d’itérations sur les campagnes complexes. La cohérence de ton sur de longues sessions supprime des frictions réelles dans les workflows de content marketing. MRCR v2 (+37 pts) garantit une bien meilleure tenue des consignes sur les contextes longs.
Si vos prompts ont été calibrés sur plusieurs mois pour GPT-5.4, la migration demande un travail de réduction et de simplification. OpenAI recommande de repartir du minimum viable, pas de porter l’existant tel quel. Le résultat justifie l’effort mais l’effort existe.
GPT-5.4 reste le bon choix pour les tâches à fort volume avec contrainte budgétaire stricte : son tarif d’entrée de 2,50 $/M tokens est deux fois moins cher. Si vos tâches sont courtes, votre contexte limité et vos prompts déjà optimisés, il n’y a pas de raison de migrer. En revanche, pour les cas d’usage à haute valeur — campagnes complexes, contenus longs, workflows multi-étapes où les hallucinations coûtent cher — GPT-5.5 justifie la différence de tarif.
Approche concrète : prenez votre prompt marketing le plus utilisé, réduisez-le au minimum fonctionnel, testez les résultats sur GPT-5.5. Si la qualité tient, déployez. Sinon, ajustez l’instruction centrale avant d’ajouter des contraintes.