48% des requêtes affichent désormais un AI Overview sur Google, contre environ 30% un an plus tôt, un bond de 58% en 12 mois (BrightEdge, mars 2026). Schema.org aide Google à cartographier les entités de vos pages. ChatGPT et Perplexity, eux, ne lisent pas votre site de la même façon que Googlebot : leurs crawlers retiennent d’abord le texte visible, rarement le balisage JSON-LD isolé. Pour être vu par les deux, il faut dupliquer chaque fait qui compte dans les deux couches et non se contenter d’empiler du balisage.
Vous avez sans doute déjà lu 10 articles listant les 8 mêmes types de balisage schema.org, sans jamais dire lequel commencer en premier ni comment vérifier qu’il sert vraiment à quelque chose. Ce guide sépare les deux mécanismes (Google d’un côté, les moteurs conversationnels de l’autre) et donne les outils pour les tester.
Ce que Google fait réellement avec votre balisage schema.org
Schema.org (un vocabulaire commun publié conjointement par Google, Microsoft, Yahoo et Yandex depuis 2011) décrit vos données pour les machines. Concrètement il indique qu’un auteur nommé a publié un article à une date donnée ou qu’un produit affiche un prix et une note moyenne. Google en tire des résultats enrichis : étoiles, prix affichés, FAQ dépliables, fil d’Ariane.
En mai 2026, la documentation officielle de Google Search Central a tranché publiquement : « Les données structurées ne sont pas requises pour la recherche générative par IA et aucun balisage schema.org spécifique n’est nécessaire. Il reste toutefois conseillé de continuer à les utiliser en complément d’une stratégie SEO globale, car elles aident à l’éligibilité aux résultats enrichis. » (traduction)
Cela ne dispense pas d’utiliser schema.org. Le balisage reste le canal le plus fiable pour transmettre des faits structurés au Knowledge Graph, qui alimente une partie des réponses d’AI Overviews. Il perd simplement son statut de sésame magique pour la visibilité IA au sens large.
Pourquoi ChatGPT et Perplexity ne crawlent pas comme Googlebot
Googlebot indexe votre page dans son intégralité, y compris les scripts JSON-LD, pour nourrir un graphe de connaissances construit depuis 15 ans. Le crawler de recherche d’OpenAI (OAI-SearchBot) et PerplexityBot fonctionnent différemment : ils opèrent surtout par récupération à la volée, un mécanisme proche du RAG (retrieval-augmented generation) que ChatGPT utilise aussi pour ses agents connectés à des outils externes. Ce mécanisme relève du tool use, la capacité d’un modèle à interroger un service externe avant de répondre. Le modèle ne parcourt pas votre site en continu, il interroge un index (souvent celui de Bing pour OpenAI) au moment de la question, puis synthétise une réponse à partir des passages de texte extraits.
Le JSON-LD est techniquement lisible par ces crawlers puisqu’il s’agit d’un simple bloc texte, sans JavaScript à exécuter. Le problème arrive à l’étape suivante : les extracteurs qui isolent le contenu principal d’une page (souvent inspirés des lecteurs de type Mozilla Readability) traitent le texte visible en priorité ; les métadonnées cachées passent au second plan. Un fait qui n’existe que dans le balisage a de bonnes chances de ne jamais atteindre la synthèse finale d’un agent conversationnel, aussi large que soit sa fenêtre de contexte.
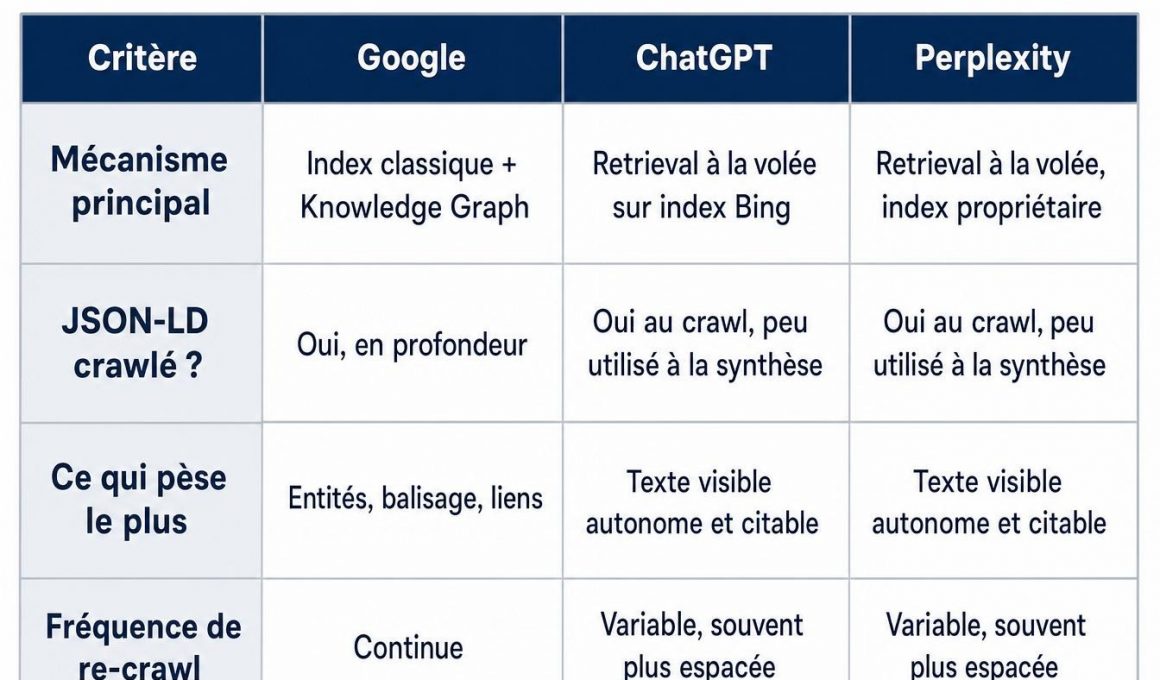
| Critère | Google (recherche + AI Overviews) | ChatGPT (recherche web) | Perplexity |
|---|---|---|---|
| Mécanisme principal | Index classique + Knowledge Graph | Retrieval à la volée sur index Bing | Retrieval à la volée, index propriétaire |
| JSON-LD crawlé ? | Oui, en profondeur | Oui au crawl, peu utilisé à la synthèse | Oui au crawl, peu utilisé à la synthèse |
| Ce qui pèse le plus | Entités, balisage, liens | Texte visible autonome et citable | Texte visible autonome et citable |
| Fréquence de re-crawl | Continue | Variable, souvent plus espacée | Variable, souvent plus espacée |
Le mythe llms.txt et l’étude sur 300 000 domaines
llms.txt promettait un raccourci. C’était un fichier à la racine du site, au format Markdown, censé résumer le contenu pour les IA comme robots.txt le fait pour le crawl classique. SE Ranking a analysé 300 000 domaines en 2026. Le taux d’adoption plafonne à 10,13% après 18 mois de battage médiatique. Surtout, aucune corrélation statistique n’apparaît entre la présence d’un llms.txt et la fréquence de citation par les IA. Un modèle prédictif a même gagné en précision quand les chercheurs ont retiré cette variable de l’analyse.
Aucun laboratoire majeur (OpenAI, Anthropic, Perplexity, Google) ne s’est officiellement engagé à le lire. Le fichier reste anecdotique. Autant concentrer le temps disponible sur le balisage et le texte, les deux leviers qui produisent un effet mesuré.
Les types de schema.org qui comptent pour la double visibilité
4 types couvrent la majorité des cas pour un site de contenu ou un service B2B. Article ou BlogPosting pour chaque page éditoriale, avec l’auteur, la date de publication et la date de mise à jour renseignées. Organization une seule fois, sur la page d’accueil, pour ancrer votre marque comme entité reconnue. FAQPage sur les articles qui répondent à 3 à 5 questions distinctes, à condition que ces questions apparaissent aussi, mot pour mot, dans le corps du texte. HowTo pour les tutoriels qui listent des étapes numérotées.
Product, Review, LocalBusiness et Event ne s’appliquent que si vous vendez un produit, collectez des avis, tenez un point de vente physique ou organisez des événements. Les ajouter sans contenu réel derrière (un Review sans avis vérifiable, un HowTo sans étapes détaillées) expose à une pénalité manuelle de Google pour balisage trompeur, documentée dans les consignes aux webmasters.
Écrire le texte pour qu’il soit citable, pas seulement balisé
Avant de dire que c’est de la théorie sans déploiement réel derrière, un test simple suffit : ouvrez un article publié et demandez-vous si un paragraphe isolé, sans titre ni contexte, répond seul à la question posée par le lecteur. Si la réponse tient en une ou deux phrases autonomes en haut de section, elle devient citable telle quelle par un agent qui synthétise une réponse à partir de plusieurs sources.
La structure en pyramide inversée aide : la réponse factuelle d’abord, l’explication et la nuance ensuite. Un système prompt d’agent IA qui construit une réponse cherche des fragments courts et autonomes. Les paragraphes qui supposent d’avoir lu les 3 paragraphes précédents survivent rarement à l’extraction. Chaque fait cité dans votre balisage schema.org (un prix, une date, un nom d’auteur) doit donc apparaître aussi, en clair, dans une phrase du texte.
Les erreurs qui ruinent le travail déjà fait
Le balisage contredit le texte visible ? Un prix affiché à 49 euros dans le JSON-LD et à 59 euros sur la page suffit à faire ignorer les deux par Google et à produire une réponse fausse si un agent IA cite le mauvais chiffre.
Les questions de la FAQPage n’apparaissent nulle part dans le corps du texte ? Le balisage devient une coquille vide, invisible pour tout crawler qui ne traite pas le JSON-LD en priorité.
Le contenu principal se charge en JavaScript côté client ? OAI-SearchBot et PerplexityBot ne l’exécutent pas systématiquement. Le rendu côté serveur reste la valeur sûre.
Valider avant de considérer le travail terminé
Le Rich Results Test de Google repère les erreurs de syntaxe JSON-LD en quelques secondes. Google Search Console, dans le rapport Améliorations, signale les balisages qui échouent silencieusement à l’échelle du site entier, sans distinction page par page. Le validateur indépendant validator.schema.org complète le tableau en vérifiant la conformité au vocabulaire schema.org lui-même, indépendamment de ce que Google choisit d’afficher.
Pour la partie ChatGPT et Perplexity, aucun outil équivalent officiel n’existe encore. La méthode la plus fiable reste artisanale : poser directement la question que vise votre article à GPT-5, à Claude Opus 4.7, à Gemini 2.5 ou directement à Perplexity, puis vérifier si votre page remonte dans les sources citées. Les agents connectés via MCP (Model Context Protocol) à des outils de recherche externes fonctionnent sur le même principe de récupération. Répétez le test chaque trimestre. Les classements de citation bougent aussi vite que les classements SEO classiques.
La priorité si vous ne devez faire qu’une chose cette semaine
Reprenez vos 5 pages les plus consultées. Vérifiez que chaque fait présent dans leur balisage schema.org (auteur, date, prix, note) figure aussi en clair dans une phrase du texte visible. Corrigez les écarts avant d’ajouter le moindre nouveau type de balisage. C’est la seule action qui profite à la fois à Google et aux moteurs conversationnels, sans dépendre d’un standard encore incertain comme llms.txt.
Un fait qui ne vit que dans une balise finit par n’exister nulle part.


