Le 5 février 2026, Anthropic a dévoilé Claude Opus 4.6, son modèle d’intelligence artificielle le plus avancé à ce jour. Cette annonce marque un tournant stratégique dans la course aux capacités agentiques, avec l’introduction d’Agent Teams permettant à plusieurs agents IA de collaborer simultanément sur des tâches complexes. Alors que 40 % des applications d’entreprise intègrent désormais des agents IA contre moins de 5 % en 2024 selon Gartner, Claude Opus 4.6 positionne Anthropic en concurrent direct d’OpenAI qui a lancé GPT-5.3 Codex quelques jours plus tard.
Claude Opus 4.6 : le nouveau modèle phare d’Anthropic
Claude Opus 4.6 est le modèle d’IA le plus performant d’Anthropic lancé le 5 février 2026, surpassant son prédécesseur Opus 4.5 de 190 points Elo sur GDPval-AA et introduisant un context window d’1 million de tokens ainsi que la fonctionnalité Agent Teams pour la collaboration multi-agents.
Claude Opus 4.6 améliore significativement les compétences de codage, planifie avec plus de rigueur les tâches agentiques longues et opère de manière plus fiable dans des bases de code volumineuses. Le modèle excelle particulièrement en révision de code et en débogage, deux compétences critiques pour les équipes de développement en entreprise.
Les domaines d’amélioration couvrent plusieurs axes techniques. Anthropic a optimisé les capacités de raisonnement multidisciplinaire avec le score le plus élevé sur Humanity’s Last Exam, un test complexe évaluant la compréhension conceptuelle avancée. Le modèle démontre également une meilleure persistance lors de tâches nécessitant plusieurs étapes séquentielles sans supervision constante.
Parmi les nouvelles fonctionnalités figure l’adaptive thinking, le mode de réflexion recommandé pour Opus 4.6. Claude décide dynamiquement quand et combien réfléchir en fonction de la complexité de la requête. Au niveau d’effort par défaut (high), Claude active presque systématiquement ce mode de réflexion approfondie, ce qui réduit les hallucinations et améliore la qualité des réponses sur des sujets techniques.
Le modèle est disponible sur claude.ai, via l’API Anthropic et sur toutes les plateformes cloud majeures incluant Amazon Bedrock, Google Cloud Vertex AI et Snowflake Cortex AI. Cette distribution multiplateforme facilite l’intégration dans les environnements d’entreprise existants sans migration infrastructure.
Agent Teams : la collaboration multi-agents en action
Agent Teams permet à plusieurs instances Claude de travailler simultanément sur différents aspects d’un projet, avec une session leader coordonnant le travail et des agents teammates communiquant directement entre eux sans créer de goulot d’étranglement informationnel.
Contrairement aux subagents qui opèrent dans une seule session et ne peuvent rapporter que des résultats au agent principal, Agent Teams supprime complètement ce goulot. Les teammates s’envoient des messages mutuellement, revendiquent des tâches depuis une liste partagée et résolvent des problèmes de manière collaborative et autonome.
Les cas d’usage les plus pertinents incluent la recherche et la révision avec plusieurs teammates enquêtant simultanément sur différents aspects d’un problème, le développement de nouveaux modules ou fonctionnalités où chaque teammate possède une portion distincte du code, le débogage avec hypothèses concurrentes permettant de tester différentes théories en parallèle, et la coordination cross-layer pour des changements touchant frontend et backend simultanément.
| Scénario | Configuration Agent Teams | Gain de temps estimé |
|---|---|---|
| Débogage complexe | 3 agents testant hypothèses parallèles | 60-70 % |
| Développement feature multi-couches | 1 lead + 3 teammates (frontend, backend, tests) | 50-65 % |
| Recherche documentation technique | 4 agents investigant sources différentes | 70-80 % |
| Révision de code large codebase | 1 lead + 2 reviewers sur modules séparés | 45-55 % |
Agent Teams reste une fonctionnalité expérimentale désactivée par défaut. Les développeurs doivent ajouter CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS dans leur fichier settings.json ou leurs variables d’environnement pour l’activer dans Claude Code. Cette approche prudente reflète le stade de maturité de la technologie et permet à Anthropic de collecter des données d’usage avant un déploiement généralisé.
La consommation de tokens augmente significativement avec Agent Teams car chaque teammate dispose de son propre context window. L’utilisation de tokens évolue linéairement avec le nombre de teammates actifs, ce qui nécessite une évaluation coût-bénéfice selon les projets. Pour des tâches critiques où la rapidité d’exécution justifie le surcoût, Agent Teams offre un ROI positif selon les premiers retours d’utilisateurs.
Performances et benchmarks comparatifs
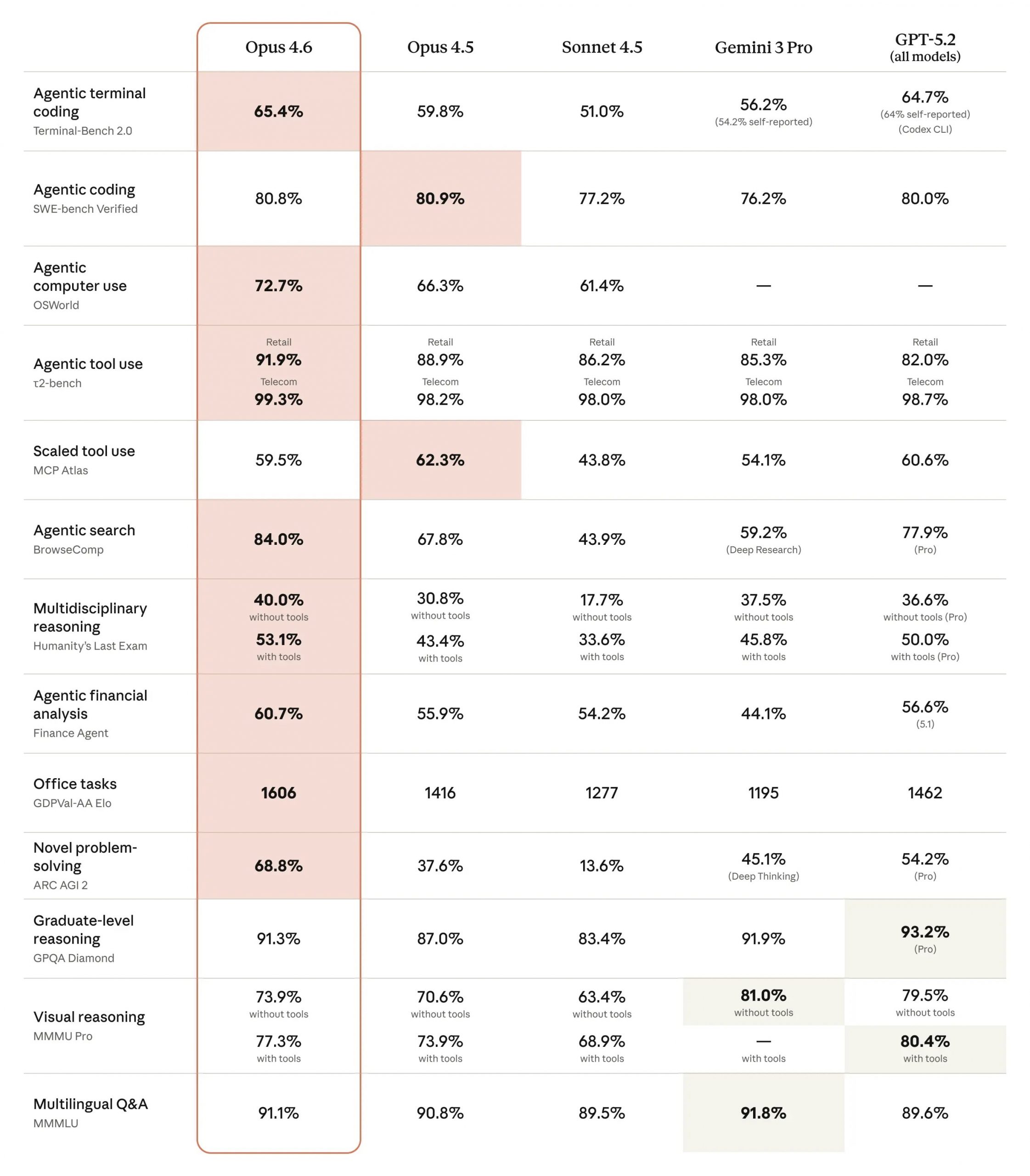
Claude Opus 4.6 atteint 65,4 % sur Terminal-Bench 2.0 (meilleur score d’évaluation de codage agentique) et surpasse GPT-5.2 de 144 points Elo sur GDPval-AA, qui mesure la performance sur des tâches de knowledge work en finance et juridique.
Sur les benchmarks de raisonnement avancé, Opus 4.6 domine Humanity’s Last Exam avec le score le plus élevé parmi tous les modèles frontière existants en février 2026. Ce test multidisciplinaire évalue la capacité à connecter des concepts abstraits à travers plusieurs domaines de connaissance, simulant des défis intellectuels complexes.
| Benchmark | Claude Opus 4.6 | GPT-5.2 | Écart |
|---|---|---|---|
| Terminal-Bench 2.0 | 65,4 % | 64,7 % | +0,7 pt |
| GDPval-AA (Elo) | Non divulgué | Non divulgué | +144 Elo |
| OSWorld (computer use) | 72,7 % | Non divulgué | Leader industrie |
| GPQA Diamond | Non divulgué | Légèrement supérieur | GPT-5.2 en tête |
Des tests indépendants sur 48 heures comparant Opus 4.6 et GPT-5.3 Codex montrent qu’Opus 4.6 génère un code cohérent et production-ready avec moins d’erreurs d’authentification et de gestion de fichiers. Sur une série de prompts standardisés, Claude Opus 4.6 a surpassé GPT-5.3 Codex sur tous les tests sauf un, avec une égalité sur le dernier.
En termes de computer use, Claude Opus 4.6 obtient 72,7 % sur OSWorld, confirmant son statut de meilleur modèle pour l’utilisation autonome d’interfaces informatiques. Cette capacité ouvre des perspectives pour l’automatisation de workflows impliquant des interactions avec des applications desktop et web sans API dédiée.
Context window d’1 million de tokens : un tournant technique
Claude Opus 4.6 introduit un context window d’1 million de tokens en version bêta, score 76 % sur MRCR v2 (8-needle à 1M de contexte) contre 18,5 % pour Sonnet 4.5, représentant un bond qualitatif en fiabilité long-contexte.
Cette capacité change radicalement les cas d’usage possibles. Les développeurs peuvent désormais charger des codebases entières de taille moyenne dans un seul contexte, permettant des analyses cross-fichiers sans fragmentation artificielle. Les analystes financiers peuvent traiter des rapports annuels complets de plusieurs centaines de pages avec leurs annexes techniques dans une requête unique.
Le score de 76 % sur MRCR v2 signifie que Claude Opus 4.6 retrouve avec précision des informations spécifiques même lorsqu’elles sont enfouies au milieu d’1 million de tokens de contexte. Ce test utilise la méthodologie « needle in haystack » où l’IA doit localiser 8 informations précises dispersées dans un volume massif de texte distracteur.
Pour les requêtes dépassant 200 000 tokens d’entrée sur Claude Opus 4.6 avec le context window d’1M activé, Anthropic applique automatiquement des tarifs premium long-contexte. Cette tarification différenciée reflète les coûts computationnels supplémentaires liés au traitement de contextes étendus tout en rendant accessible cette capacité pour les cas d’usage justifiant l’investissement.
Le modèle peut également générer jusqu’à 128 000 tokens en sortie, soit environ 96 000 mots. Cette limite de génération permet de produire des documents techniques complets, des rapports d’audit détaillés ou du code structuré pour des applications complètes sans nécessiter de concaténation manuelle.
Tarification et disponibilité
Claude Opus 4.6 coûte 5 dollars par million de tokens d’entrée et 25 dollars par million de tokens de sortie, avec des économies jusqu’à 90 % via prompt caching et 50 % via batch processing, maintenant le même pricing qu’Opus 4.5.
Anthropic n’a pas augmenté les tarifs malgré les améliorations substantielles de performance, une stratégie compétitive face à OpenAI. Le prompt caching permet de réutiliser des portions de contexte déjà traitées dans les requêtes précédentes, réduisant drastiquement les coûts pour les workflows répétitifs analysant des documents similaires ou utilisant des system prompts constants.
Le batch processing offre 50 % de réduction en acceptant un délai de traitement différé. Cette option convient parfaitement aux tâches non-urgentes comme l’analyse de datasets volumineux, la génération de rapports nocturnes ou le traitement de backlog de tickets de support client.
| Option tarifaire | Réduction | Cas d’usage optimal |
|---|---|---|
| Tarif standard | 0 % | Requêtes temps réel, interactions utilisateur |
| Prompt caching | Jusqu’à 90 % | System prompts constants, documents réutilisés |
| Batch processing | 50 % | Analyses différées, traitement bulk datasets |
| US-only inference | -10 % (surcoût) | Contraintes réglementaires de localisation données |
Pour les organisations nécessitant que leurs données restent sur le territoire américain, Anthropic propose une option US-only inference avec un surcoût de 10 % sur Claude Opus 4.6 et les modèles plus récents. Cette offre répond aux exigences de conformité réglementaire de secteurs comme la santé (HIPAA) ou la finance soumise à des restrictions de souveraineté des données.
Le modèle est immédiatement accessible sur claude.ai pour les utilisateurs individuels, via l’API Anthropic pour les développeurs et sur Amazon Bedrock, Google Cloud Vertex AI et Snowflake Cortex AI pour les déploiements entreprise. Cette disponibilité multiplateforme simultanée contraste avec les lancements précédents où les plateformes cloud recevaient l’accès avec plusieurs semaines de décalage.